코딩 테스트 전날 까먹는 문법들을 정리한 것이다!
따라서 기본적인 JOIN / SubQuery 문법은 다루지 않고
내가 자주 까먹는 것만 ~~
WITH RECURSIVE
자기 자신을 참조하여 쿼리를 실행한다.
WITH RECURSIVE CNT
AS (
-- Non-Recursive 문장 : 첫번째 루푸에서만 실행된다.
SELECT 1 AS n
UNION ALL
-- Recursive 문장 : 읽어올 때마다 행의 위치가 기억되며 다음 행으로 이동한다.
SELECT n + 1 AS num
FROM CNT
WHERE n < 5 # 종료조건
)
SELECT * FROM CNT;
정규표현식
REGEXP 또는 RLIKE를 사용하여 정규 표현식 매핑
SELECT *
FROM your_table
WHERE column_name REGEXP '^a.*z$';'^a.*z$'
- ^a : 문자열이 'a'로 시작
- .* : 중간에 어떤 문자든 올 수 있음
- z$ : 문자열이 z로 끝남
'[0-9]'
- [0-9] : 숫자 범위 문자가 포함된 문자열 찾기
'(abc|ABC)'
- (abc|ABC) : 대소문자 관계 없이 abc를 포함하는 문자열 찾기
'^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}$'
- ^[A-Za-z0-9._%+=]+ : 알파벳 대소문자, 숫자, 특수문자 중 하나 이상으로 시작
- @[A-Za-z0-9.-]+ : @뒤에 도메인 이름
- \.[A-Za-z]{2,}$ : '.' 뒤에 최소 2자 이상의 알파벳 확장자1) .
- 기능 : 임의의 문자 / 어떠한 문자든 하나의 자리를 차지할 수 있다는 의미
- 예시 : 'a.b' : a 뒤에 임의의 문자하나 이후 b가 오는 패턴 (a1b, acb (O) ab (X))
2) ^
- 기능 : 문자열의 시작을 나타냄
- 예시 : ^a : a로 시작하는 지 확인 (apple (O) banana(X))
3) $
- 기능 : 문자열의 끝을 나타냄
- 예시 : z$ : z로 끝나는지 확인 (buzz (O) bus (X))
4) *
- 기능 : a가 0번 이상 반복될 수 있음
- 예시 : a* : a가 0번 이상 반복되는 경우 (aaa, a, "" (O))
5) +
- 기능 : 1개 이상의 문자가 반복될 수 있음을 나타낸다.
- 예시 : a+ : "aaa", "a"는 매칭되지만 ""는 매칭되지 않는다.
6) ?
- 기능 : 0개 또는 1개의 문자가 있음 해당 문자가 있을 수도 있고, 없을 수도 있다.
- 예시 : a?b : a가 0번 또는 1번 나오고 그 뒤에 b가 있는 패턴 찾는다 (ab, a (O) aab (X))
7) []
- 기능 : 대괄호 중 하나와 매칭
8) -
- 기능 : 범위
9 [^ ]
- 기능 : 대괄호 안의 문자들 외의 문자와 매칭된다. 부정의 의미!!
- 예시 : [^0-9]는 숫자가 아닌 문자와 매칭
내가 정의한 이메일의 조건
- 첫번째 문자는 소문자
- 대소문자를 구분하지 않고, 알파벳과 숫자, 특수문자 -, _를 허용
- @ 기호 앞의 문자열에 적용
SELECT *
FROM your_table
WHERE email_column REGEXP '^[a-z][a-zA-Z0-9-_]*@gmail\\.com$';순위 함수
1. RANK() OVER (ORDER BY 컬럼 DESC) AS 이름
- 동점이 있을 경우 동일한 순위 부여
SELECT
EMP_NO,
NAME,
SALARY,
RANK() OVER (ORDER BY SALARY DESC) AS SALARY_RANK
FROM EMPLOYEES;
SELECT
EMP_NO,
NAME,
DEPARTMENT,
SALARY,
RANK() OVER (PARTITION BY DEPARTMENT ORDER BY SALARY DESC) AS SALARY_RANK
FROM EMPLOYEES;
- PARTITION_BY는 각 컬럼 별로 데이터를 그룹화한다. (예시 : 부서 별로 급여 순위를 따로 매긴다)

2. DENSE_RANK() OVER (ORDER BY 컬럼 DESC) AS 이름
- 동일한 값에 같은 순위를 부여하지만, 그 다음 순위를 건너뛰지는 않는다.
SELECT
EMP_NO,
NAME,
SALARY,
DENSE_RANK() OVER (ORDER BY SALARY DESC) AS SALARY_DENSE_RANK
FROM EMPLOYEES;
3. PERCENT_RANK() OVER (ORDER BY 컬럼) AS 이름
상대 순위함수로 현재 행 값에 대해 0 ~ 1사이의 상대값을 리턴한다.
SELECT
employee_id,
salary,
PERCENT_RANK() OVER (ORDER BY salary) AS percent_rank
FROM
employees;
4. ROW_NUMBER() OVER (ORDER BY 컬럼) AS 이름
- 순위를 매기되, 동일한 값이라도 고유한 순위를 부여한다.
SELECT
EMP_NO,
NAME,
SALARY,
ROW_NUMBER() OVER (ORDER BY SALARY DESC) AS SALARY_ROW_NUMBER
FROM EMPLOYEES;
5. NTILE(n) OVER (ORDER BY 컬럼) AS 이름
- 데이터를 n개의 그룹으로 나누고 그룹 번호를 부여한다.
SELECT
EMP_NO,
NAME,
SALARY,
NTILE(3) OVER (ORDER BY SALARY DESC) AS SALARY_NTILE
FROM EMPLOYEES;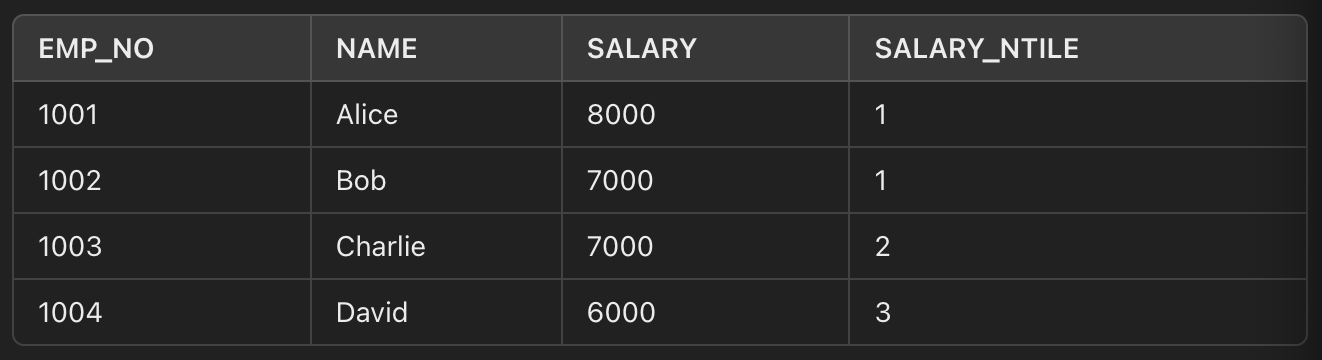
DISTINCT
중복을 배제하고 고유값만 출력
SELECT DISTINCT col1, col2, ... From table_name비트 연산자
1. AND 연산자 (&)
- 1: 읽기 권한
- 2: 쓰기 권한
- 4: 관리자 권한
SELECT USER_ID, ROLE
FROM USERS
WHERE ROLE & 4 = 4;2. OR 연산자 (|)
두 숫자 중 하나라도 1이면 1을 반환
- 1 | 2 = 3
SELECT USER_ID, ROLE
FROM USERS
WHERE ROLE & (1 | 4) > 0;
3. XOR 연산자 (^)
XOR 연산자는 두 숫자의 비트가 서로 다를 때 1을 반환
SELECT USER_ID, ROLE
FROM USERS
WHERE (ROLE ^ 5) < 5;
LIKE 사용법
- % : n개 문자 혹은 여러 문자를 의미
- _ : 하나의 문자를 의미
1. % 예시
(시작) 'A'로 시작하는 모든 고객을 조회하세요
SELECT CUSTOMER_ID, NAME
FROM CUSTOMERS
WHERE NAME LIKE 'A%';
(끝) '@gmail.com' 으로 끝나는 모든 고객을 조회하세요
SELECT CUSTOMER_ID, EMAIL
FROM CUSTOMERS
WHERE EMAIL LIKE '%@gmail.com';
(중간) 문자 중간에 free 패턴 찾기
SELECT PRODUCT_ID, DESCRIPTION
FROM PRODUCTS
WHERE DESCRIPTION LIKE '%free%';
숫자가 포함된 문자열 찾기
SELECT PRODUCT_ID, DESCRIPTION
FROM PRODUCTS
WHERE DESCRIPTION LIKE '%[0-9]%';2. _ 예시
제품 코드가 두 번째 문자가 'X'인 제품을 찾으시오.
SELECT PRODUCT_ID, PRODUCT_CODE
FROM PRODUCTS
WHERE PRODUCT_CODE LIKE '_X%';SELECT PRODUCT_ID, PRODUCT_CODE
FROM PRODUCTS
WHERE PRODUCT_CODE LIKE 'A_0%' OR PRODUCT_CODE LIKE 'A_1%' OR PRODUCT_CODE LIKE 'A_2%'
OR PRODUCT_CODE LIKE 'A_3%' OR PRODUCT_CODE LIKE 'A_4%' OR PRODUCT_CODE LIKE 'A_5%'
OR PRODUCT_CODE LIKE 'A_6%' OR PRODUCT_CODE LIKE 'A_7%' OR PRODUCT_CODE LIKE 'A_8%'
OR PRODUCT_CODE LIKE 'A_9%';
UNION
- UNION : 중복 제거
- UNION ALL : 중복 제거를 하지 않는다.
UNION을 할 때 반드시 두 SELECT 문의 컬럼이 일치해야 한다.
SELECT NAME, CITY
FROM CUSTOMERS_A
WHERE CITY = '서울'
UNION
SELECT NAME, CITY
FROM CUSTOMERS_B
WHERE CITY = '부산';SELECT NAME, CITY
FROM CUSTOMERS_A
UNION ALL
SELECT NAME, CITY
FROM CUSTOMERS_B;수학 함수
- ABS(): 절댓값을 반환
- CEIL() 또는 CEILING(): 소수점 값을 올림
- FLOOR(): 소수점 값을 내림
- ROUND(column, 3): 소수점 값을 반올림
- POWER(column , 2): 제곱 연산을 수행
- SQRT(): 제곱근을 계산
- MOD(column, 2): 나머지 값을 반환
문자열 함수
- CONCAT(): 문자열을 연결합니다.
- SUBSTRING(): 문자열의 일부를 추출합니다.
- LENGTH(): 문자열의 길이를 반환합니다.
- UPPER(): 문자열을 대문자로 변환합니다.
- LOWER(): 문자열을 소문자로 변환합니다.
- TRIM(): 문자열의 공백을 제거합니다.
- REPLACE(): 문자열의 일부를 다른 문자열로 대체합니다.
- INSTR(): 문자열 내 특정 문자열의 위치를 반환합니다.
- LEFT(): 문자열의 왼쪽에서 지정한 길이만큼 반환합니다.
- RIGHT(): 문자열의 오른쪽에서 지정한 길이만큼 반환합니다.
1. CONCAT()
SELECT FIRST_NAME, LAST_NAME, CONCAT(FIRST_NAME, ' ', LAST_NAME) AS FULL_NAME
FROM CUSTOMERS;
2. SUBSTRING(컬럼, 시작 숫자, 몇개의 숫자)
SELECT PHONE, SUBSTRING(PHONE, 1, 3) AS AREA_CODE
FROM CUSTOMERS;
3. TRIM() : 앞 뒤 공백 제거
SELECT NAME, TRIM(NAME) AS TRIMMED_NAME
FROM CUSTOMERS;
4. REPLACE() : 문자 일부 대체
SELECT PHONE, REPLACE(PHONE, '-', '') AS CLEAN_PHONE
FROM CUSTOMERS;
4. INSTR() : 특정 문자열 위치 찾기
SELECT EMAIL, INSTR(EMAIL, '@') AS AT_POSITION
FROM CUSTOMERS;
5. LEFT() / RIGHT() : 문자열의 (왼쪽 / 오른쪽) 에서 일정 길이 만큼 추출
SELECT ZIP_CODE, LEFT(ZIP_CODE, 5) AS ZIP_SHORT
FROM CUSTOMERS;
6. SUBSTRING_INDEX (column, 기호, 인덱스)
특정 구분자를 기준으로 문자열을 나누고 @ 앞부분만 가져올 수 있다.
SELECT
SUBSTRING_INDEX(email_column, '@', 1) AS local_part
FROM your_table;
소수점 자리 맞추기
1. FORMAT() : 숫자를 문자로 변환
제품 가격을 소수점 둘째 자리로 고정하여 표시하시오.
SELECT PRODUCT_NAME, PRICE, FORMAT(PRICE, 2) AS PRICE_FORMATTED
FROM PRODUCTS;
2.TRUNCATE() : 숫자를 자르고, 소수점 이하 자리를 제거
제품 가격을 소수점 둘째 자리까지만 남기고 나머지를 제거하시오.
SELECT PRODUCT_NAME, PRICE, TRUNCATE(PRICE, 2) AS PRICE_TRUNCATED
FROM PRODUCTS;
3. CAST() : 소수점 고정
SELECT PRODUCT_NAME, PRICE, CAST(PRICE AS DECIMAL(10, 2)) AS PRICE_FIXED
FROM PRODUCTS;
날짜 관련 함수
- CURRENT_DATE(): 현재 날짜를 반환합니다.
- NOW(): 현재 날짜와 시간을 반환합니다.
- DATE_ADD(): 특정 날짜에 기간을 더합니다.
- DATE_SUB(): 특정 날짜에서 기간을 뺍니다.
- DATEDIFF(): 두 날짜 간의 차이를 일 단위로 계산합니다.
- DATE_FORMAT(): 날짜를 특정 형식으로 변환합니다.
- EXTRACT(): 날짜에서 특정 부분(연도, 월, 일 등)을 추출합니다.
1. DATE_ADD() / DATE_SUB() : 날짜에 기간을 더하기 / 빼기
SELECT ORDER_ID, ORDER_DATE, DATE_ADD(ORDER_DATE, INTERVAL 10 DAY) AS ESTIMATED_DELIVERY
FROM ORDERS;
2. DATEDIFF() : 두 날짜 간의 차이 계산
SELECT ORDER_ID, ORDER_DATE, DELIVERY_DATE, DATEDIFF(DELIVERY_DATE, ORDER_DATE) AS DAYS_BETWEEN
FROM ORDERS;
3. DATE_FORMAT() : 날짜 형식변환
SELECT ORDER_ID, ORDER_DATE, DATE_FORMAT(ORDER_DATE, '%m/%d/%Y') AS FORMATTED_DATE
FROM ORDERS;
4. EXTRACT() : 날짜에서 특정 부분 추출
고객의 생년월일에서 태어난 연도만 추출하여 출력하시오.
SELECT CUSTOMER_ID, BIRTH_DATE, EXTRACT(YEAR FROM BIRTH_DATE) AS BIRTH_YEAR
FROM CUSTOMERS;
5. YEAR(), MONTH(), DAY(): 날짜에서 연도, 월, 일을 추출
- YEAR(ORDER_DATE): 주문 날짜에서 연도만 추출.
- MONTH(ORDER_DATE): 주문 날짜에서 월만 추출.
- DAY(ORDER_DATE): 주문 날짜에서 일만 추출.
SELECT ORDER_ID, ORDER_DATE,
YEAR(ORDER_DATE) AS ORDER_YEAR,
MONTH(ORDER_DATE) AS ORDER_MONTH,
DAY(ORDER_DATE) AS ORDER_DAY
FROM ORDERS;
6. TIMESTAMPDIFF(): 두 날짜 또는 시간 간의 차이를 구하는 함수
고객의 주문 시간과 배송 시간 간의 차이를 시간 단위로 계산하시오.
SELECT ORDER_ID, ORDER_TIMESTAMP, DELIVERY_TIMESTAMP,
TIMESTAMPDIFF(HOUR, ORDER_TIMESTAMP, DELIVERY_TIMESTAMP) AS HOURS_BETWEEN
FROM ORDERS;